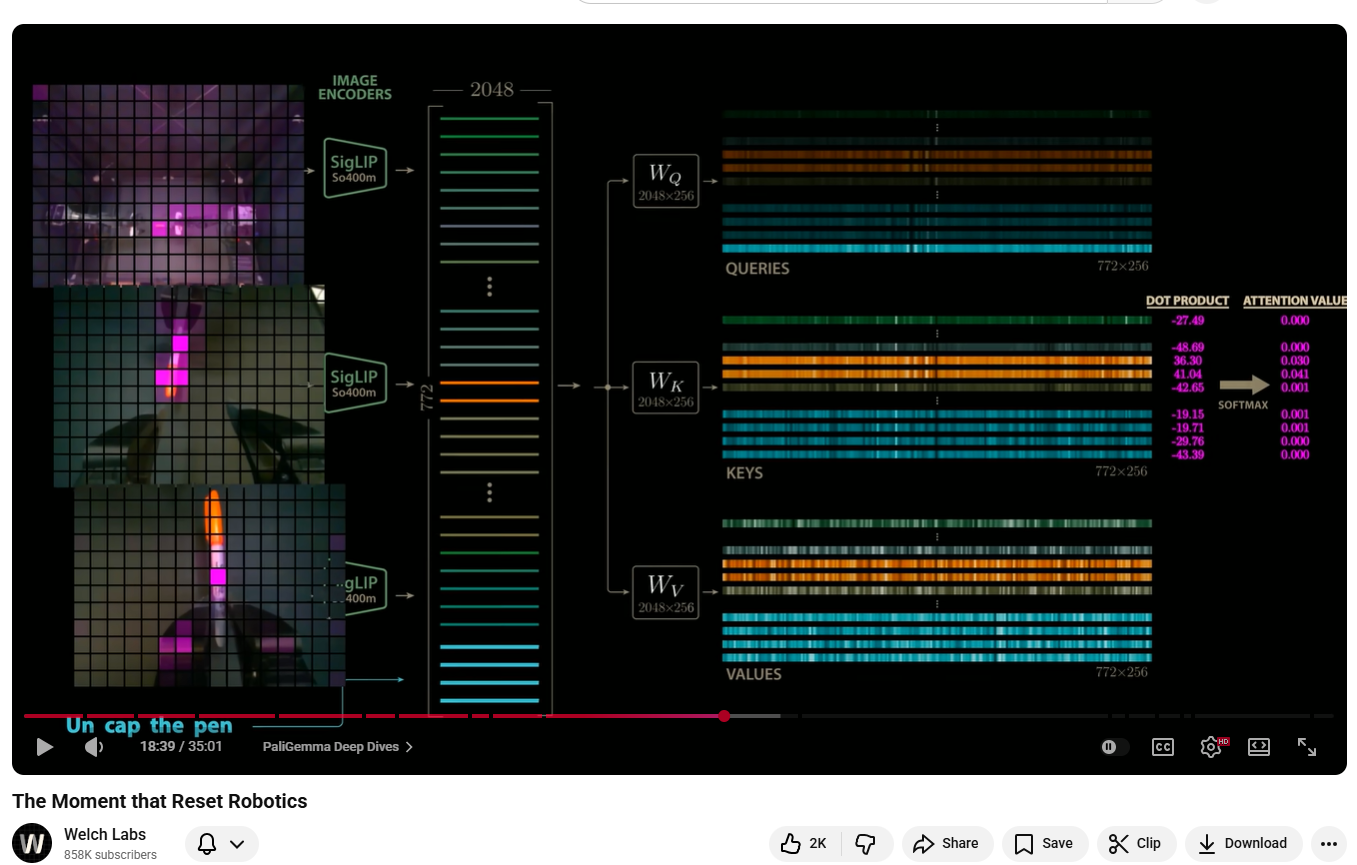
At 18 minutes and 39 seconds into a YouTube video about robotics, something philosophically strange becomes visible. A heatmap. Three camera feeds. And the word pen. The frame shows the internals of PI Zero — a vision-language-action model built by Physical Intelligence, a startup assembled from many of the key members of Google's robotics team. Three cameras are trained on a scene: one overhead, two mounted at the wrists of a two-armed robot. Each camera's feed is broken into a grid of 256 patches. The patches from all three cameras are encoded by SigLIP image encoders into 768 embedding vectors, each of length 2048, before being projected down to 256 dimensions and concatenated into a single stream. Alongside them, four text tokens arrive: un, cap, the, pen. All 772 vectors enter Gemma's attention mechanism together. What happens next is worth pausing on.
The Computation
Each attention head multiplies the incoming embeddings by three matrices of learned weights — W_Q, W_K, W_V — producing queries, keys, and values of shape 772 × 256. This is not symbolic manipulation in any traditional sense. There is no lookup table, no rule that says "pen corresponds to orange cylindrical objects." The query vector for the final token, pen, is a dense 256-dimensional pattern of floating-point numbers that the model has learned, through training on human demonstrations, to associate with certain visual configurations. It is then compared against every key vector via dot product — 772 comparisons, each producing a scalar.
The dot products visible in that frame are all negative: −27.49, −48.69, −36.30, −41.04, −42.65, continuing down the list. This is not unusual — raw dot products in high-dimensional attention are often large in magnitude and negative. What matters is the relative ordering. After softmax normalisation, nearly all 772 values resolve to 0.000. Two do not. The two image patches that visually contain the pen score 0.030 and 0.041 — small numbers in absolute terms, but larger than all others by orders of magnitude. Those patches are copied, weighted, and added to the pen position in the value output. In a single forward pass, the model has formed a unified representation of the word and the thing it refers to in the physical world.
What the video then shows — playing this analysis frame by frame as the robot attempts to uncap the pen — is that this grounding is not a coincidence of a single frame. The two bright patches of attention track the pen across all three camera views as the scene changes. The model is doing something that looks very much like sustained, cross-modal object tracking: the semantic token pen continuously finding its physical referent in three simultaneous streams of visual data.
The attended values are then passed downstream. PI Zero's action expert — a second network that shares Gemma's architecture but is randomly initialised and more compact — receives the language model's key and value matrices directly via a shared cache. It does not receive a description of where the pen is. It receives the representational output of the attention that found the pen. From this, using a process borrowed from image generation called flow matching, it iteratively refines a random matrix of joint-position trajectories into a smooth 50-step plan for moving 14 actuators. A process designed to synthesise images of cats is here being used to synthesise motion. The robot reaches for the pen because the word pen matched those orange patches, and those patches told the trajectory planner where to go.
What the Word Already Knew
PI Zero is built on PaLiGemma, a combination of SigLIP and Gemma. Gemma is a large language model pre-trained on text alone. It had never seen an image. It had never held a pen, felt its weight, or watched one roll off a table. Yet the Gemma component arrives at this joint architecture carrying something — carrying enough latent structure about the concept pen that, once paired with image encoders, it can reliably locate a physical pen in novel scenes without being explicitly told what one looks like. Where did that structure come from?
The text corpus is not a neutral symbolic system. It is a compressed record of embodied interaction with the world. Every narrative about picking something up, every description of a pen running dry, every instruction manual explaining how to uncap a marker — all of it encodes, implicitly, a model of physical behaviour. George Lakoff and Mark Johnson argued in Metaphors We Live By (1980) that abstract conceptual structure is not arbitrary but is grounded in physical experience, and that this grounding propagates into language. Their core claim was that the spatial, force-dynamic, and object-interaction schemas of embodied experience become the deep structure of thought — and therefore of speech. A large language model, trained to predict the next token across this corpus, is not merely learning statistical regularities in character sequences. It is — incidentally, without being asked — distilling the physical intuitions of everyone who ever wrote anything down.
The question is not whether the model has grounded the symbol. The question is whether grounding was ever the model's job — or whether language was always already grounded, and the model simply absorbed what was already there.
This is not a new theoretical position. Charles Sanders Peirce's semiotics had argued something structurally similar over a century earlier. Peirce distinguished between icons (signs that resemble their referent), indices (signs causally connected to their referent), and symbols (arbitrary conventional signs). Language is largely symbolic in Peirce's sense — the word pen does not look like a pen. But Peirce always insisted that symbols are not free-floating: they are ultimately grounded in iconic and indexical relations that were established through actual encounters with the world. The symbol inherits the structure of the encounters that produced it. Wittgenstein's later work arrived at a related conclusion from a different direction: meaning is use, and use is embedded in forms of life — in the physical, social practices within which language is deployed. You cannot fully separate the word pen from the activity of writing, holding, uncapping. The meaning of the word includes the body that uses the thing.
What LLMs add to this conversation is not a new theory. It is an empirical demonstration. You can now train a system with zero explicit physics and zero embodiment, on pure text, and then measure how much physical structure it recovers. The fact that it recovers enough to reliably locate a pen in a novel visual scene — enough to ground a gripper trajectory — is not a refutation of embodied cognition theory. It is, arguably, its strongest empirical confirmation. If language had not always already encoded physical structure, the experiment would have failed.
The Map Inside the Weights
There is now direct empirical evidence for what this structure looks like. In 2023, Wes Gurnee and Max Tegmark published a study — "Language Models Represent Space and Time" — that asked a precise question of GPT-style models: if you take the internal activations at a given layer and fit a linear probe to them, can you recover physical coordinates? Geographic latitude and longitude? Dates on a timeline? The answer, across multiple model families and scales, was yes. Not with a complex nonlinear decoder. A linear probe.
The linearity is the finding. It means the model has not merely memorised "Paris is in France" as a retrievable fact. It has arranged the concept Paris in activation space such that its direction from other concepts encodes actual geographic distance and cardinal relationship. London is northwest of Paris not just as a proposition the model can assert, but as a structural property of where those tokens live in the geometry of the model's internal representations. The 14th century is before the 15th not just as something the model knows, but as something encoded in the direction of a vector. Physical and temporal structure have been carved into the shape of the space itself.
This is what the linear representation hypothesis, in its strong form, claims: that the features a language model develops to solve its prediction task tend to be linearly encoded in activation space, and that for features which correspond to real-world structure — space, time, causation, physical properties — the linear encoding preserves the relational geometry of the world. The model did not choose this. It is a consequence of training on a corpus generated by agents embedded in a structured physical reality. The world has metric properties; language inherits them; the model, recovering the generative structure of the language, recovers the structure of the world.
Tegmark's broader framing pushes this further. If the corpus was generated by a physical world with particular causal and geometric structure, then a model with sufficient capacity, trained to predict that corpus, is implicitly being trained to model the world that generated it. Language is not an arbitrary veil over reality. It is a lossy but structured projection of reality — and sufficiently powerful models invert that projection, recovering the hidden structure. What reads as "next token prediction" from the outside is, from another angle, something closer to world-model induction.
Return now to the attention heatmap. When the query vector for pen resonates with the key vectors of orange cylindrical patches across three camera views, it is not doing something categorically different from what Gurnee and Tegmark's probes found. The model has arranged pen in activation space such that its representational neighbourhood is geometrically close to the visual and physical features of pens — their shape, their typical context, the grip required to hold one, the action of uncapping. These features are not stored as explicit attributes. They are encoded as directions in a high-dimensional space that the model learned in order to predict text. The semantic and the perceptual are spatially adjacent in the same manifold. The attention mechanism, computing dot products between queries and keys, is in this light something like a nearest-neighbour search in a space that was organised, through training, to reflect the structure of reality.
This reframes what the PI Zero engineers actually built. They did not construct a bridge between semantics and physics. They gave an existing bridge — already latent in the language model's weights, already encoding the geometry of the world — a set of sensors and actuators. The bridge was there. PI Zero gave it a body to cross into.
The Taylor Swift Problem
One year before PI Zero, in 2023, Google's RT2 demonstrated something that clarified the stakes. A researcher set up a table with a Coke can and photographs of several celebrities, including Taylor Swift. The robot was asked to move the can to Taylor Swift. Taylor Swift appeared nowhere in the robot control training data. For the task to succeed, the model — built on the PaLI-X multimodal language model fine-tuned to output motor control signals — had to transfer a concept formed entirely from internet-scale pre-training into a spatial grounding that could direct a physical gripper.
It worked. The robot slowly picked up the Coke can and placed it on the edge of the photograph. One of the researchers on the team would later describe this as the moment it became clear that the approach was going to work. What made it a watershed was not the grace of the movement — the robot was slow and awkward — but what it proved about the representational structure of language models. The semantic cluster around "Taylor Swift" in a text-trained model contains enough visual information, absorbed through image captions, descriptions, reviews, and the incidental visual grounding of billions of sentences, to identify her photograph among other photographs on a table. The internet, distilled into weights, reached into a physical scene.
The RT2 team coined a name for this class of model: vision-language-action, or VLA. The name is apt because it names the bridging operation: vision (physical scene), language (semantic structure), action (physical intervention). The question of whether semantics and physics have been bridged is, in one reading, just the question of whether VLA models work. And they do work — imperfectly, with important caveats, but measurably and reproducibly.
The Dissenters
Not everyone finds this convincing as a bridge. Yan LeCun, speaking in the same video, is direct: "VLAs are doomed." His objection is not that the semantic-physical connection doesn't exist. It is that routing through language is the wrong architecture for physical intelligence. LeCun's alternative — broadly called world models, and the basis for his new venture after leaving Meta — proposes that AI systems should learn physics more natively, through direct prediction of sensory consequences of actions, without the detour through linguistic representation. On this view, a system that learned to reach for a pen by predicting the visual and proprioceptive consequences of arm movements would be more robust, more generalisable, and less brittle than one that does it by matching the token pen to image patches.
The predictive processing framework in neuroscience, associated with Karl Friston and Andy Clark, makes a related but distinct point. On this account, the brain does not store grounded representations and then retrieve them when needed. It runs forward models — hierarchical generative models that constantly predict sensory input and update on prediction error. Perception is not retrieval; it is prediction. When you read the word pen, you are not accessing a stored image of a pen. You are generating a cascade of predictions about what a pen looks like, how it would feel in your hand, what your arm would do to reach it. The attention heatmap in the PI Zero video shows you the spatial grounding; it is the flow matching process — iterative, trajectory-shaped, forward-modelling — that is more neurologically plausible as an account of what the action system is actually doing.
There is also the harder philosophical objection, which John Searle raised in 1980 in the Chinese Room argument and which has not been definitively resolved since. Searle's claim was that syntactic manipulation — symbol processing according to formal rules — cannot, in principle, constitute semantic understanding. The system that matches pen to orange patches is doing something that looks like grounding. But is the model understanding what a pen is, or is it executing a learned pattern that correlates, reliably but contingently, with the right outputs? The heatmap is evidence of successful function. It is not, by itself, evidence of understanding in whatever richer sense Searle had in mind.
What Remains Open
The question this leaves open is not whether something has been built. A robot picks up a pen because a word appeared in a prompt. The causal chain is real and measurable: token to query vector, query to attended patches, patches to cached keys and values, keys and values to trajectory, trajectory to actuator. That chain exists. It works. The bridge, in some functional sense, is there.
The question is what kind of bridge it is. Is it an engineering artefact — a useful but fragile approximation, dependent on the distributional accidents of what humans happened to write down, liable to fail whenever the world diverges from the implicit physics of the text corpus? Or is it evidence of something deeper: that language and physical reality share enough structural overlap that a sufficiently expressive model of one becomes, necessarily, a partial model of the other? Lakoff and Johnson, Peirce, and Wittgenstein each had reasons to think the structural overlap is not accidental — that language could not function as it does if it were not already deeply shaped by the physical world. The VLA experiments are now providing something those arguments could not: a quantitative test. Train on language, measure physical generalisation. The results are not perfect, but they are not zero.
There is also the question of what you are doing when you read the word pen. Neuroscience suggests that motor cortex and visual cortex activate in response to reading action words and concrete object words — that reading is not purely symbolic even in humans. The attention head connecting pen to orange patches in three camera views might be less alien to human cognition than it first appears. It might be, in a coarser and more explicit form, something structurally similar to what happens in the visual cortex when the concept of a pen is activated by language. The bridge, if it exists, may not have been built for the first time by these models. It may be that these models have, for the first time, made the bridge visible.
What else could semantics and physics possibly be — if not, at some level, the same structure, described from two different vantage points: one from inside language, one from inside the world?
Addendum — On the Inverted Path
There is one objection to the VLA approach that deserves a more direct answer than it usually receives. LeCun's "grounding directionality" argument — that these models start from language, which is already a highly processed, symbolically mediated representation, and try to ground downward into physical reality, whereas a true world model should be built upward from raw sensorimotor experience — is usually treated as a straightforwardly damning observation. It should not be.
The argument assumes that what language loses in its projection from physical experience is strictly a deficit — that the shadow is always less than the object. But this is only true if the goal is to recover full-fidelity physical reality. If the goal is to act intelligently within it, the losses may look different. Language does not merely compress physical experience. It filters it. Every concept that has survived long enough to be stably encoded in a shared vocabulary has passed through an enormous implicit relevance test — thousands of people, across centuries and cultures, found it useful enough to transmit. The discretisation that LeCun frames as impoverishment is also, simultaneously, a crowd-sourced distillation of what physical structure actually matters for agents like us.
These are genuinely different inductive paths to overlapping knowledge, each with characteristic losses and characteristic gains. The toddler's path is richer in certain dimensions — the felt resistance, the precise timing, the proprioceptive loop, the ten thousand unrepeatable particulars of direct encounter. The language path is richer in others — scope, counterfactual coverage, second and third-order knowledge, physical reasoning conducted by minds across centuries and compressed into reusable abstract form. Andrej Karpathy's framing of jagged intelligence is useful here: the jaggedness of a language-grounded physical reasoner is not random. It is structured by the shape of what language encodes well and what it encodes poorly. We should expect these systems to be preternaturally capable where physical knowledge has been heavily verbalised — and to have characteristic holes where it was tacit, embodied, never written down. The sommelier's palate. The exact feel of a joint about to fail. The muscle memory of a backhand.
But the alien quality of this approach is also, I think, something we underestimate. VLA models are not attempting to replicate human embodied intelligence by a different route. They are doing something genuinely novel — building physical competence top-down from the most abstract layer of human knowledge representation. Nothing has ever done this before. The toddler-to-adult development path has been running for hundreds of thousands of years and we have calibrated intuitions about its ceiling. The language-down path has been running at scale for perhaps three years. Extrapolating its ceiling from current performance — and concluding, as LeCun does, that it is fundamentally bounded — is a strong claim to make about a process we have barely observed.
There is also the question of whether the gap is static. Every time a robot operating on a language-model brain encounters the physical world and that experience is folded back into training, the tacit becomes explicit, the embodied becomes verbalised, the sensorimotor becomes propositional. The distance between what language encodes and what physical reality contains is not a fixed quantity. It is a surface being eroded from both sides simultaneously — abstract structure pressing downward, physical experience pressing upward. The question of ceiling is really the question of how much of physical reality is, in principle, verbalisable. The answer to that question, across the full arc of human history, has consistently turned out to be: more than anyone previously thought.